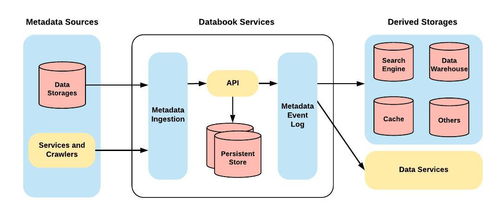
作为全球领先的出行平台,Uber的业务模式天然产生海量数据——从乘客的叫车请求、司机的行驶轨迹,到实时的交通状况、动态的定价策略,每分每秒都在生成TB级别的数据。这些数据不仅是Uber运营的副产品,更是其核心资产。通过构建强大的大数据服务体系并运用先进的数据可视化技术,Uber将这些看似杂乱的数据转化为深刻的商业洞察与卓越的用户体验,驱动着平台的智能化与高效化。
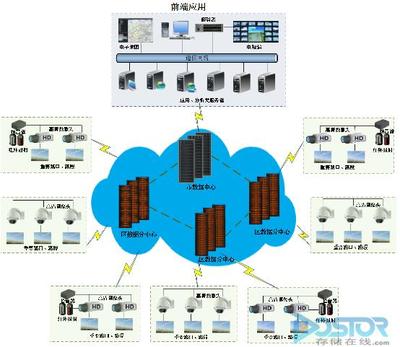
Uber的大数据服务体系建立在坚实的技术架构之上。其数据管道从移动端、服务器和第三方服务实时收集原始数据,经过清洗、转换与聚合,存储于如Hadoop、Spark等分布式系统中。这一体系的核心目标是为全公司提供统一、可靠、可扩展的数据服务,支持从实时风险监控到长期战略分析的各种需求。例如,ETA(预计到达时间)预测模型就依赖历史行程数据与实时交通流数据,通过机器学习不断优化,其准确性直接影响用户体验与司机调度效率。
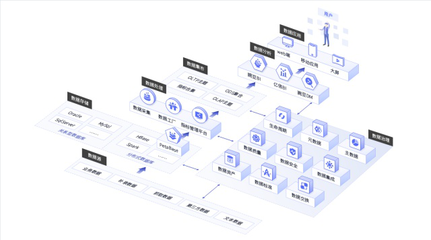
原始数据本身价值有限。Uber深谙此道,因此将数据可视化作为释放数据价值的关键桥梁。可视化实践将复杂的分析结果转化为直观的图表、地图和仪表盘,使得不同角色的员工——从工程师、产品经理到城市运营团队——都能快速理解数据背后的故事,并据此做出决策。
一个著名的实践案例是Uber自主开发的可视化工具"Kepler.gl"。这是一个开源的地理空间分析工具,能够处理大规模的位置数据并将其在交互式地图上生动呈现。城市运营团队可以利用它分析不同区域的出行需求热点、司机在线时长分布,从而优化激励策略和资源调配。例如,通过将乘客叫车起点热力图与实时交通拥堵图层叠加,运营者可以一目了然地识别出供需失衡的区域,并即时采取措施。
另一个关键的可视化应用体现在内部的数据平台上。Uber构建了统一的指标仪表盘,将核心业务指标(如总行程数、司机活跃度、乘客满意度等)以动态图表的形式实时展现。这使得管理层能够像查看汽车仪表盘一样,随时掌握业务的“健康状况”。当某个城市的订单取消率异常上升时,仪表盘会触发警报,并通过关联的可视化分析,帮助团队迅速定位原因——是定价问题、司机不足,还是局部天气影响。
Uber还将数据可视化用于提升透明度与信任。面向司机端的应用程序中,清晰地可视化了行程收入明细、奖励区域(如高峰溢价区)以及热力图,帮助司机更有效地规划工作。面向乘客,则通过简洁的界面展示车辆实时位置、行驶路线和费用构成,增强了服务可信度。
Uber的数据可视化实践并非一蹴而就,其成功基于几个重要原则:首先是“以用户为中心”,确保可视化产品服务于具体的决策场景和用户认知习惯;其次是“性能与规模”,能够高效处理与渲染全球级别的海量数据;最后是“开放与创新”,通过开源部分工具(如Kepler.gl)与学术界、业界共享知识,共同推动技术进步。
Uber将大数据服务视为引擎,而数据可视化则是让这个引擎的效能清晰可见、可操控的仪表盘。通过这一紧密结合的实践,Uber不仅优化了内部的运营效率与决策质量,更将数据的力量渗透到产品与服务的每一个环节,塑造了其以数据驱动为核心竞争力的现代科技企业典范。在迈向更加自动化与智能化的未来出行进程中,大数据与可视化必将持续扮演不可或缺的角色。